
In net 3 sekondes kan 'n KI wat jou nog nooit hoor praat het nie, jou stem perfek naboots. Dit is die jongste prestasie van Microsoft se kunsmatige intelligensie: die VALL-E-spraaksintese-model, wat enigiemand se stem na goeddunke kan kopieer met net 3 sekondes se spraak.
Microsoft VALL-E sal ons stem naboots na net 3 sekondes se praat
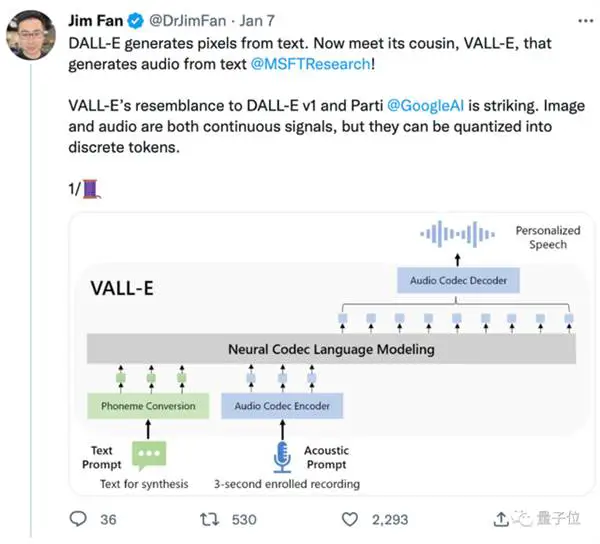
Dit het van DALL·E ontstaan, maar spesialiseer in die klankveld, en die teks-na-spraak-effek het gewild geword nadat dit aanlyn vrygestel is.
Sommige gebruikers het gesê dat as VALL·E en ChatGPT gekombineer word, die resultaat ongelooflik sal wees. Vir ander blyk dit dat die dag wanneer dit moontlik sal wees om video-oproepe met KI te maak nie ver is nie. Daar is ook diegene wat 'n grap maak deur daarop te wys dat nadat die KI met skrywers en skilders te doen gehad het, die stemakteurs volgende is.

Maar hoe boots VAL·E 'n "ongehoorde" klank binne 3 sekondes na?
ALL-E ontleed oudio met taalmodelle. Sintetiseer spraak gebaseer op "ongehoorde" KI-klanke, dit wil sê nul-steekproefleer.
Die tradisionele teks-na-spraak-oplossing is basies 'n voor-opleidingsmodus saam met fyninstelling. As dit in 'n nul-steekproef-scenario gebruik word, sal dit lei tot swak ooreenkoms en natuurlikheid van die spraak wat gegenereer word.

Op grond hiervan is VAL-E uit niks gebore, wat 'n ander idee voorstel in vergelyking met die tradisionele stemmodel.
In vergelyking met die tradisionele model wat Mel-spektrum gebruik om kenmerke te onttrek, beskou VALL-E spraaksintese direk as die taak van die taalmodel, eersgenoemde is kontinu en laasgenoemde is diskreet.
In die besonder is die tradisionele spraaksinteseproses dikwels die pad van “foneem → mel-spektrogram (mel-spektrogram) → golfvorm”.
Maar VALL·-E het hierdie proses omskep in "foneem→diskrete oudiokodering→golfvorm":
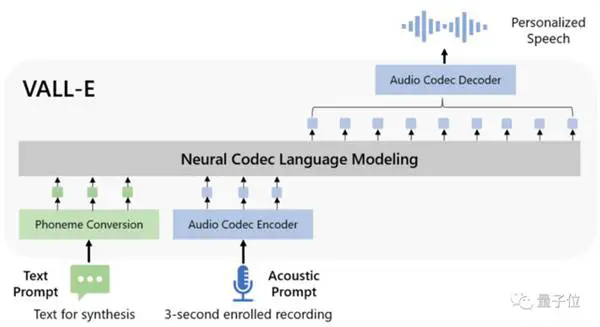
Wat modelontwerp betref, is VAL-E ook soortgelyk aan VQVAE. Kwantiseer oudio in 'n reeks diskrete tokens. Die eerste kwantiseerder is verantwoordelik vir die vaslegging van die oudio-inhoud en spreker-identiteitskenmerke, terwyl die tweede kwantiseerders verantwoordelik is vir die verskerping van die sein. wat meer natuurlik klink:
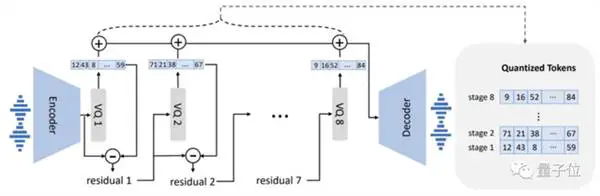
Dan gekondisioneer deur die teks en die 3-sekonde oudio-opdrag, stuur dit outoregressief 'n diskrete oudio-kodering uit:
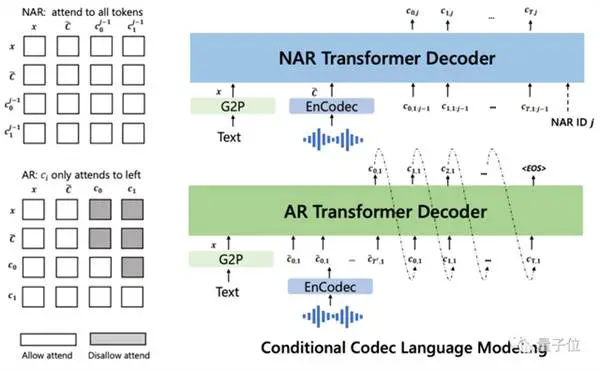
Maar nie net dit nie, benewens nul-steekproef-spraaksintese, ondersteun VALL-E ook stemredigering en steminhoudskepping gekombineer met GPT-3.
Omringende agtergrondklank kan ook herstel word
Te oordeel aan die gesintetiseerde vokale effekte, kan VALL-E meer as net die spreker se timbre herstel.
Nie net word die toon op die plek nageboots nie, maar dit ondersteun ook 'n verskeidenheid verskillende praatsnelhede. Byvoorbeeld, dit is twee verskillende spraaktempo's wat deur VALL-E verskaf word wanneer dieselfde sin twee keer uitgespreek word, maar die timbrale ooreenkoms is steeds hoog:
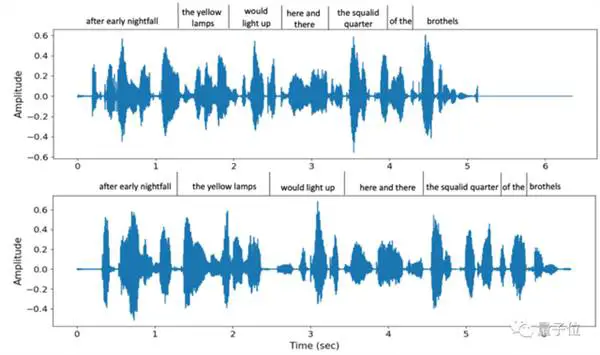
Terselfdertyd kan die omringende agtergrondklank van die gespreksgenoot ook akkuraat herstel word.
Daarbenewens kan VALL-E 'n verskeidenheid spreker-emosies naboots, insluitend verskillende tipes soos kwaad, slaperig, neutraal, blymoedig en naar.
Dit is die moeite werd om te noem dat die datastel wat vir VALL·E-opleiding gebruik word nie besonder groot is nie.
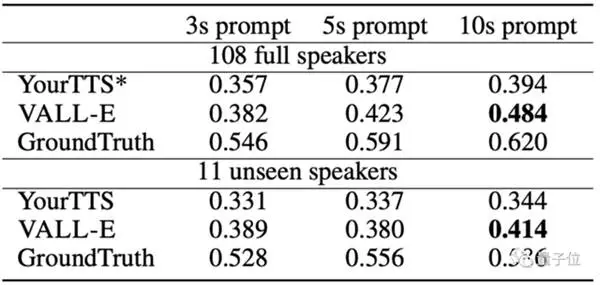
In vergelyking met OpenAI se Whisper, wat 680.000 7.000 uur se oudio-opleiding vereis het en net meer as 60.000 XNUMX luidsprekers en XNUMX XNUMX ure se opleiding gebruik het, het VALL-E beter as voorafopgeleide spraaksintese gevaar in terme van Model YourTTS-spraakooreenkoms.
Verder het YourTTS die stemme van 97 van die 108 sprekers vooraf tydens opleiding gehoor, maar nogtans te kort geskiet aan ALL-E in die werklike toets.
Wat die velde betref waarin dit toegepas kan word:
Dit kan nie net gebruik word om jou eie stem na te boots nie, byvoorbeeld om gestremde mense te help om 'n gesprek met ander te voltooi, maar jy kan dit ook gebruik om namens jou te praat wanneer jy nie wil nie. Dit kan natuurlik ook gebruik word om oudioboeke op te neem.
VALL-E is egter nog nie oopbron nie en jy sal dalk 'n bietjie langer moet wag om dit uit te probeer.
Aangebied op Amazon







